

-
1 Introduction
Resolving disputes is one of the fundamental aspects of human society. Mechanisms underlying these processes have been built upon reliable data storage technology (tablets, paper) and communication means of an era. Although developments in these fields in the last decades have not been mature enough for this fundamental aspect to transition safely into the online world, they are, now.
A key element of trust or mistrust in online dispute resolution is connected to the online access to justice. Trustworthy access to justice denotes providing informed and relatively easy access to online justice to all people, independently of their abilities and vulnerabilities. A key element of trustworthy access to justice for all is diversity by design.1x Top authorities on this topic are Ayelet Sela and David Larson.
Diversity by design has not been implemented in practice mainly because it would be too costly to design, implement and maintain by any single ODR platform, no matter how big it is.2x Based on discussions with ODR experts, including Ayelet Sela and David Larson. There are too many vulnerabilities, too many languages, etc. In addition, there are technology constraints: each ODR platform would need to be extremely flexible, with huge plasticity, appearing differently to each user or small groups of users with shared traits.
The future of ODR is in data-driven Artificial Intelligence (AI)-assisted processes. With the help of AI, we believe that diversity by design is achievable, provided all the inherent risks connected with the application of AI are addressed.
We believe there are two critical assumptions for improving access to justice for people in a forward-looking perspective, closely related to each other. Effective control of data by those who generate the data, i.e. mainly people, and also symmetric relation between the parties so that each party can fully represent itself in the online world, will be essential for balanced access to justice for all.
In order to enable these critical assumptions, there is the need for not only new approaches to the ODR procedures and related new (AI-based) services, but importantly also new, alternative approaches to online technology architectures. With such a new technology infrastructure, platforms will be technologically similar, to a significant extent, for all the parties, including people and SMEs, as well as for ODR institutions. Even platforms for individual people and SMEs will need to include independent data stores, as well as asynchronous digital communication via messaging and addressing among platforms at a mass scale. We explain more on the topic of this alternative online infrastructure later in Section 2.3 called Open framework for messaging and addressing.
These online platforms will mediate the party’s interactions with other involved parties (e.g. vendors, individual persons, public institutions or ODR providers) and their platforms acting on the party’s behalf as its virtual agent. Thus, we call such platforms Virtual Agent Platforms (VAPs).
In this article, we argue that the challenges of access to justice in e-justice ODR will be more easily and more efficiently achievable via an approach alternative to the one which has been discussed and attempted in the current e-justice ODR theory and practice. The new approach serves to enable the parties which can best assess, with the help of new digital tools and AI, their abilities and vulnerabilities, to personalize for themselves the e-justice ODR forms which they need and which can be communicated to e-justice/ODR platforms and be understood by these platforms.
It means that an ODR platform of an e-justice ODR institution will not need to have the built-in plasticity to handle various types of preferences and vulnerabilities, but it will need to understand all different forms accommodating weaknesses or preferences by the parties who file them. We argue that the main reason why this proposed alternative approach can achieve better results than the current theory and practice lies in the collaboration among users-data generators, mainly individual citizens.
They can voluntarily share their data in anonymized form with other users with similar demands who will not need to replicate the development of such data (e.g. related to a particular vulnerability and language). They can also collaborate in the distributed training of new AI services, helping them to constantly improve the services they use and thus helping them more and more in resolving their dissatisfactions.
These new AI services should be available to all parties, including mainly to all persons with all possible digital vulnerabilities. They will be available in a specific online space which we call Online Common Space. Online Common Space will have many other public AI services serving users in other fields besides e-justice ODR.
Our main topics described in this article do not have an impact only on the field of ODR but might also apply to other fields of human activities in the online universe. -
2 Open ODR Standard
The starting point for developers of such new ODR platforms (VAPs) and new AI services for the parties is an open standard describing data-driven e-justice ODR processes. This article attempts at proposing such a standard, under the working name Open ODR.
The open standard will enable the parties’ and ODR providers’ platforms to securely exchange data assisting in resolving their dissatisfactions, including but not limited to data about:Helping to prepare personalized ODR forms for the party, reflecting his/her preferences and needs, or finding the best-suited forms available;
Assisting the party in selecting the ODR option and ODR provider by processing disclosure information of various ODR providers and their available evaluations;
Navigating their users to access “advice or assessment portals” with information on access to justice in particular situations (e.g. how to file a tenant’s complaint against a fraudulent accommodation provider) and guidelines on how to prepare relevant documents (e.g. an application for social benefits). Once such advise portals are based on open specifications, they will be able to provide such navigation globally (e.g. to assist Chinese tourists with their issues in Prague);
In addition, the standard will enable VAPs to inform the user whether the seller has available concrete features which empower customers (e.g. access to ODR and efficient protection of privacy); where customers should file their feedback and/or complaints against a particular seller; where expressly invited sellers may send their information to the particular customer or potential customer in which the customer is interested; where customers should send their information to the particular seller about issues they care about. Moreover, users will be able to inform any seller about their key preferences (e.g. that they care for strong protection of their personal data or for an efficient ODR).
Open ODR will have the following core components:Open data framework for ODR;
Open specification of the first publicly available AI services for the parties assisting them in personalizing their access to ODR and resolving their issues; and
Open framework for messaging and addressing among online platforms (VAPs) in the e-justice ODR field.
All these components are integrated with one another; the public AI services form an integral part of the new forward-looking standard of e-justice ODR processes and are as such described by the open data framework. Messaging and addressing enable the creation of data models for developers on top of the open data framework and thus make the data framework operable in practice. Key outcomes of the open data framework will be the standard digital characteristics of each VAP, its digital twin. Parts of the digital twin of a VAP will be necessary for addressing and messaging among VAPs. We call such parts “VAP Door Codes”.
2.1 Open Data Framework
We understand the open data framework for e-justice ODR as standard open digital mapping of e-justice ODR processes which is: (i) widely open and flexible; (ii) focuses on cross-platform understandability and communication; (iii) ensures effective protection of privacy and digital security; and (iv) is easy to implement in VAP platforms as well as in ODR platforms which will not be VAPs.
The purpose of digital mapping is to describe all or almost all e-justice ODR processes in full detail and in a form understandable to both people and machines. This may encompass different aspects, including the process logic, the user forms or the User Interface (UI).2.1.1 Standard Digital Tools for the Mapping
Fortunately, many digital tools have been developed over the years and are currently available for free, which can fulfil these requirements. These tools may be very diverse and include standards, data formats and notations. The key aspect is that they can be easily used by both machines and people (even people that are not technical experts). Thus, they support the communication between people (including people of different backgrounds), and between people and machines, significantly facilitating the development of solutions that require this multi-disciplinarity, such as the case of ODR platforms.
Several widely used standards can be used to design archetypes or specific ODR platforms, some of which are mentioned next. Business Process Model and Notation (BPMN) is a graphical modelling language used to represent business processes visually. It provides a standardized notation that can be easily understood by business users, developers and stakeholders. BPMN is designed to provide a common language and framework for describing, analysing and improving business processes. It consists of a set of symbols and conventions for representing activities, events, gateways, flows and artefacts which can be used to model both simple and complex business processes. BPMN models can be used for a variety of purposes such as documenting current processes, designing new processes and analysing and improving existing processes.
Some tools, such as Camunda, also allow for the actual user forms to be designed and associated with specific tasks. This allows not only to test the actual processes from the user’s point of view but also to deploy them into a server available online. That is, the whole process can be deployed in the form of a functional process-oriented web application.
One key aspect that both BPMN and forms connected to it have in common is that, although depicted visually, they are modelled using structured languages. Specifically, BPMN diagrams are modelled as Extensible Markup Language (XML) documents while forms are modelled as JavaScript Object Notation (JSON) documents.
XML and JSON are both widely used formats for representing structured data in a human-readable and machine-readable format.
XML is a markup language that uses tags to define elements, attributes and values, making it easy to structure and organize data. It is widely used for data interchange between different systems and platforms. XML can be used to represent complex data structures, and it is extensible, meaning that users can define their own tags and elements. XML documents can be validated against a defined schema, making it easier to ensure data consistency and quality.
JSON, on the other hand, is a lightweight data-interchange format that uses a key-value pair structure to represent data. It is often used in web applications and APIs because it is easy to parse and can be read by JavaScript. JSON is simpler than XML and typically takes up less space, making it faster to transmit over a network. JSON is also extensible, and users can define custom data types.
Given the structured nature of these formats and notations, several interesting additional functionalities can be implemented that interact with the designed processes or forms. For instance, it is possible to develop tools to automatically extract the data elements associated with a specific process, sub-process or form. It is also possible to develop tools to check the consistency of the data elements (e.g. ensure no two elements with the same identifier exist) to check for missing annotations or validate other aspects such as mandatory fields and the data types of the fields. Being able to automatically inspect and validate processes and forms is also useful, for instance, when it comes to enforcing ethical guidelines (e.g. variables containing personal data identifying information should not be extracted to build an anonymous dataset from a given process).
BPMN, XML or JSON are only examples of structured digital tools, widely used to describe processes in general, and have proven to be easy to understand and use. Moreover, their standard nature means that designers and developers do not depend on a particular BPMN, XML or JSON tool, editor or application. Indeed, a wide range of licensed and open-source tools exists that allows to export, import and work with documents in such standards and notations which allows users and developers with different backgrounds to pick their favourite ones.
The issue, however, is that e-justice ODR field is very complex. It is full of exceptions, local procedures and rules and has a need for variable options. In addition, the same terminology may have different meanings, depending on a particular country or even a part of a country.3x This is very well demonstrated by Paula Hannaford-Agor in her article, Director, Center for Jury Studies, NCSC, “How exactly does it get done here?” Conducting cross-jurisdictional research with judges and court staff.
In addition, we (voluntarily) make these complexities much more complicated by advocating for diversity by design as explained in the introduction. We assume that there are a lot of different design preferences of individual people and too many digital vulnerabilities which need different designs.
Although BPMN and JSON tools enable to fulfil almost all the conditions mentioned above for our open data framework, they do not fulfil the condition of cross-platform understandability and communication. It is because each new BPMN set of e-justice ODR processes or variants of each new form in a new BPMN/JSON system will have different automatic numbering. It means that different processes, sub-processes or forms might be identified by the same automatically generated codes. Due to the complexity of the field, this happens very often.2.1.2 Need for Additional Numbering
For this reason, we argue that it is necessary to apply additional numbering for the open digital mapping which will not be lost no matter how many variants, new processes, sub-processes or forms will be created.
We propose to apply such additional numbering to the initial set of standard e-justice ODR processes and forms created in BPMN/JSON. Such an initial set has been prepared by us within our E-Justice ODR Scheme project.4x E-Justice ODR Scheme, DG JUST 101046468. The proposed initial numbering (complementary to the automatic numbering by BPMN and JSON) will create a necessary fixed basis, then the numbering of all the variants and additions can be derived from this initial numbering using standard references described in part (C) below.
Open data framework for e-justice ODR will be formed by this open numbering. Each ODR platform might have its description – its digital twin – described in this open data framework. The numbering can be used by digital tools for the design and development of online platforms (VAPs). It will then be possible to generate the digital twin automatically during the process of designing and developing the VAP.2.1.3 What Will Be Numbered and How
We finally come to the content of the digital twins for e-justice ODR. We propose that these are the following component parts of the e-justice ODR processes and their details which need to be numbered:
Design modules
Processes and sub-processes
Forms and their parts
Terminology
Ethical annotations
Communication rules
Other
Regarding the numbering as such, we propose to use a simple consecutive numbering for each of the components mentioned above. Each component will be identified by a letter (as mentioned above).
Design modules are results of general design questions about how a VAP or other-than-VAP ODR platform should look like (e.g. will there be an option of the party’s legal representation or not). Based on responses to these questions, the structure of the VAP will be set. Design questions help to define selection of features by designers of ODR platforms. According to the design selection, list of forms corresponding to the selection will be identified. We propose the following initial processes and their numbering:Number Design Question 1 Does the platform enable legal representation of the parties? 2 In which languages the platform operates? 3 What types of cases the platform helps to resolve? 4 In which fields/sectors the platform specializes? 5 Is it possible to have one’s own forms? 6 How many judges, arbitrators, mediators or panellists (judicial officers) are possible to decide cases on the platform? 7 Are judicial officers selected by the parties? 8 What forms of communication are possible on the platform? 9 Who prepares first proposal of resolution? 10 When does the decision become effective on the platform? 11 Are appeals available on the platform? 12 What procedures are available on the platform? 13 What enforcement options are being used on the platform? 14 Add new design question E-justice processes and sub-processes include traditional ones (e.g. court proceedings, arbitration and mediation) and also newly proposed AI-assisted services for the parties (e.g. assistance to select ODR). We propose the following initial processes and sub-processes (not arranged in a particular order):
Name Type Arbitration Process Court proceedings Process File complaint Sub-process Negotiation Process Recall legal representative Parallel sub-process Complaint withdrawal Parallel sub-process Prepare settlement agreement Sub-process Appeal proceedings Sub-process JO’s resignation Parallel sub-process JO’s appointment Sub-process Mediation Process Appoint legal representative Parallel sub-process Waiting for response Sub-process Fee payment Sub-process Video conference Parallel sub-process Physical hearing Parallel sub-process Prepare and issue decision Sub-process Monitor implementation Sub-process Issue recommendation Sub-process Feedback Sub-process Pre-transaction Sub-process AI assistance to select ODR Process Add new process Add new sub-process We propose the following initial list of e-justice ODR forms (not arranged in a particular order):
Name Type Linked Sub-Process Arbitration agreement signing Form Arbitration Prepare arbitration agreement Form Arbitration Selection of type of proceedings Form Court proceedings Consent with JO accessing negotiation/mediation communication Form Court proceedings Prepare and file complaint Form File complaint Review of the complaint Form File complaint Complain against complaint non-compliance notice Form File complaint Prepare and file reply Form Negotiation Complainant prepares reply Form Negotiation Settlement agreement reached Form Negotiation Notification of agreement reached by the parties Form Negotiation Complainant accepts reply Form Negotiation Respondent accepts reply Form Negotiation Recall legal representative Form Recall legal representative File appeal Form Appeal proceedings Request for JO’s resignation Form JO resignation Consideration of request for JO’s resignation Form JO resignation JO’s resignation Form JO resignation JO’s appointment Form JO appointment Invite to the initial discussion Form Mediation Schedule Mediation round by JO Form Mediation Schedule Mediation round by parties Form Mediation Settlement agreement reached Form Mediation Appoint legal representative Form Appoint legal representative Accept mandate Form Appoint legal representation Prepare and file response Form Waiting for response Review of the response Form Waiting for response Complain against response non-compliance notice Form Waiting for response Review complaint Form Waiting for response Time slot selection for video conference Form Video conference Video conference scheduling Form Video conference Witness verification Form Video conference Schedule hearing Form Physical hearing Prepare and issue decision Form Prepare and issue decision Appeal Form Prepare and issue decision Notification about non-implementation of outcome Form Monitor implementation Prepare and issued recommendation Form Issue recommendation Provide feedback Form Feedback Feedback Form Feedback Start dispute Form Feedback Reputation index Form Pre-transaction Add new form Terminology has key importance for the digital twin exercise. E-justice ODR terminology is very complex. In addition, one term might have various meanings not only in different jurisdictions but sometimes also in different courts of a single jurisdiction. These differences constitute valid legal cultures and are key for understanding the e-justice ODR processes.5x Paula Hannaford-Agor, Director, Center for Jury Studies, NCSC, “How exactly does it get done here?” Conducting cross-jurisdictional research with judges and court staff. The best practice currently is the work done over 40 years by the US National Center for State Courts.6x Ibid. Terminology needs to be under constant review and maintenance by judicial and ODR communities. In our initial set of ODR terms and their numbering, which has not yet been ready at the time of finalizing this article, we have been trying to follow the research and methodology done in the United States as much as possible.
Our initial set of terminology is being prepared in English based on the experiences in several EU jurisdictions.7x Research sub-project under the E-Justice ODR Scheme. Where possible, we take into consideration the US system, because it is the most advanced at the moment. The initial proposed terminology will be ready by the end of 2023 and will form part of the outcomes of our E-Justice ODR Scheme project.
Ethical annotations guide designers and developers on how to operationalize digital ethics. Ethical annotations for individual VAPs which make use of AI services of personalized e-justice ODR forms will be different from ethical annotations regarding access to justice for the current ODR platforms. We argue that the main differences are the following:Current ethical annotations need to be context-based which makes them, as a result, very comprehensive and variable and therefore very difficult and expensive to implement in a concrete ODR platform;
On the other hand, ethical annotations of a public AI-based service of personalization of ODR forms will be centred around AI ethics and efficient protection of personal data and therefore will be more focused;
Protection of personal data will focus on the anonymization of shared data and measures preventing de-anonymization of the shared data (e.g. aggregation);
Fundamental AI ethics will be around the trustworthiness of AI service, i.e. will include understandability and explainability, which will be key for building user awareness and trust;
Key issue will be the ethical risks of personal AI learning from each other in different contexts and communities;
AI ethical annotations will also focus on how to prevent the risk of being deceived by corporations; or prevent the personal AI to form a ‘union’ to manage us;
These ethical annotations will need to be fully or almost fully operationalized in the AI service and the VAP platforms receiving them because of the obligatory certification following the EU AI Act and similar legislation in other parts of the world;
For this reason, there will probably not be a need for a special numbering of such ethical annotations because they will be directly implemented in the actual e-justice ODR processes.
Our proposed standard (numbering) conventions for addressing and messaging are described later in Section 2.3 on the open framework for communication rules, namely addressing and messaging.
2.1.4 Proposed Numbering Convention
We propose the following hierarchical namespaces within the numbering of BPMN of e-justice ODR: any data element will have a number consisting of several digits under each ‘number position’, where each position represents a hierarchy level, as shown in the table below:
Number Position Level 0 Name of author(s); type of author; release No. 1 Design option (high-level) 1x Not-yet specified design option [Other]; [‘x’ includes the same meta data as under ‘O’ above] 2 Sub-process option 2x Not-yet specified sub-process option 3 Form option 3x Not-yet specified form option 4 Form heading option 4x Not-yet specified form heading option 5 Form sub-heading option 5x Not-yet specified sub-heading option 6 Data element option 6x Not-yet specified data element option 7 Data element characteristic: (i) text; (ii) alternative option; (iii) cumulative option; (iv) condition; (v) other 8 For condition, next heading or sub-heading There can be multiple numbers for a single data element because the same data element can relate to various design options. This is acceptable because the ensemble of numbers describes the design structure of the platform from which the data element is taken.
As mentioned above, details of these core components of many digital twins of many possible VAP platforms will be available in our E-Justice ODR Scheme8x See above note 9. at the end of 2023. The scheme will include (i) XML files; (ii) a textual description of the digital model (a checklist) and (iii) ethical annotations.2.1.5 VAP Door Codes
Parts of the digital twin of the VAP will be important for some or all other VAPs because they will enable digital communication among VAPs. We call such parts the VAP Door Codes. For example, the VAP of an individual party with a personalized complaint form will need to know the digital twin of the complaint form of the selected ODR provider so that it can pair the data in the personalized form with the ODR provider’s form.
Not all VAP users will want to have their VAP Door Codes available to other VAPs in general. Some VAPs will share their VAP Door Codes only with a few selected VAPs (e.g. for users in a family or a community) and some users will decide not to share any data with anybody, so they will not share their VAP Door Codes at all.
VAP Door Codes will be different for most VAPs not because they will need to be unique but because each user will have his or her own purposes for using the VAP which will be reflected in the VAP’s features. It might be that gradually there will be a wide group of VAP Door Codes used by most of the VAPs but this can only be ascertained by the longer use of VAP Door Codes in practice.
At the same time, each VAP Door Code will need to be tied to a unique identification of the VAP so that other VAPs can recognize that this is part of the digital twin of the VAP they are ordered to communicate with.
VAP Door Codes can be the same or very similar for the same or very similar digital twins. Nevertheless, if there are the same Door Codes for different parts of digital twins, it will be a serious mistake which we need to prevent or at least minimize. One way would be to construct and automatically apply checksum(s) of each of the VAP Door Codes which can be automatically generated together with the generation of the digital twin of a VAP. Then as the first step of messaging, one VAP would ask for the checksum and verify it before starting the communication. Another option might be some kind of central registry. There are more ways of preventing the misleading creation of VAP Door Codes.2.1.6 Simplified Numbering for Low-Code/No-Code (LC/NC) VAPs
The detailed numbering of each data element described above might be aggregated for specific building blocks from which certain types of VAPs can be built even by non-IT professional developers, using methods of LC/NC development. For example, the assemblies of the building blocks can be differentiated according to levels of complexity involved in their assembly works into the following groups, named after analogy with popular toys: (i) baby duplo; (ii) duplo; (iii) Lego; and (iv) Lego Pro. With growing awareness, users themselves, including individual users, will be able to build their own VAPs from such blocks.
Some of the building blocks will be specific to certain situations and certain types of cases (e.g. specific parts of a complaint or response forms for disputes related to online defamation cases). We believe though that it might be possible to design many ODR blocks in a way that will enable their re-utilization across various types of cases or even possibly various types of vulnerabilities. Such preparation will need more design work and specific user testing in the future.2.2 Personalization through AI
AI can play a key role in achieving the above-mentioned vision regarding access to justice, namely through its ability to ingest, process and decide upon vast amounts of information which would be unmanageable for a decision maker. Specifically, information collected from a multitude of diverse users, including, in regard to, their preferences, feedback, needs, limitations, cultural background or behaviours, can be used to shape the content of ODR platforms and its delivery, so that it is shaped to each individual user. This will significantly enhance interaction and the efficiency of access to information, ultimately allowing to realize access to justice.
There are two key dimensions that can be adapted/personalized through AI: the content that is delivered, and the way it is delivered. Both are addressed below. The third key component of personalization through AI relates to how the AI modules are trained which is also addressed below.2.2.1 Personalization of Content
The content provided in an ODR platform may be very diverse, ranging from information regarding a specific case, to statistical information for decision-support extracted from hundreds or thousands of cases, or a panoply of support services aimed at the users of the platform (e.g. parties, legal experts). In any case, these services and the information they provide can be personalized according to the user.
Let us take as an example the act of selecting an ODR platform. Without personalization, this would consist of a list of ODR providers without any particular ordering criteria. Every user would have access to the same list, and would eventually have to go through the list to select a suitable provider based on simple criteria such as location or cost. This is, nonetheless, a short-sighted approach which significantly limits the extent to which the user can optimize the decision.
We can now consider an AI-based service for the assistance in selecting an ODR platform. Here, instead of seeing a static list, the user would have access to a list of ODR providers that are suitable to her/his needs and/or limitations (e.g. geographical, economic, time-wise, communicational). Moreover, the list would be sorted according to the extent to which each provider meets the users’ preferences. This does not necessarily require a lengthy interaction with the user to acquire a detailed list of preferences/limitations, as these can be extrapolated from groups of similar users and further fine-tuned through feedback mechanisms.
Such a service would significantly improve access to justice by allowing the user to make a selection based on a smaller group of ODR providers that are, in principle, the right ones given the current case and context. This would have a positive impact on indicators such as the time to settle a case or the satisfaction of the user.
Moreover, expertise and experience are considered, ensuring that the selected platform aligns with the specific nature of the dispute. Customization, security and privacy also come into play, as the right platform provides tailored features while safeguarding sensitive information. Ultimately, assistance in selecting an ODR platform empowers individuals to navigate disputes effectively, fostering fair outcomes and satisfactory resolutions. Several AI techniques can be directly used to assist parties in selecting ODR processes.
Expert systems can be designed to provide intelligent recommendations tailored to the unique characteristics and requirements of each dispute. By analysing the input provided by the parties, expert systems can consider various factors, including the nature of the dispute, its complexity, the preferences of the involved parties and the available resources. This analysis allows the expert system to suggest suitable ODR methods that are most likely to lead to successful resolutions.
The selection of an ODR service can also be achieved through the so-called Case-based Reasoning (CBR). CBR involves leveraging a database of past cases and their outcomes to offer guidance in a current similar situation. That is, given a list of past cases (users wanting to solve a conflict and its context/characterization) and outcomes (which ODR services were selected by the users in each case), the system can now suggest an ODR service for a new situation that is similar to a group of previous known ones. This approach has the advantage that its suggestions are easy to explain/justify, based on the similarity/proximity of different features when comparing the current case with the past ones.
Machine Learning (ML) also has significant potential in assisting parties with the selection of ODR methods. By analysing historical data on ODR cases and their outcomes, ML can extract valuable insights. Supervised learning algorithms can be trained on labelled datasets, where the input variables represent case characteristics, and the labelled data indicate the corresponding ODR service used or the outcomes achieved. With this training, the algorithms can predict the most suitable ODR methods based on the given input variables.
For instance, classification models can recommend mediation or arbitration based on case characteristics, such as the nature of the dispute or the number of parties involved. On the other hand, regression models can estimate the expected resolution time or settlement amount, providing parties with valuable information for decision-making. By leveraging its power, parties can benefit from data-driven recommendations and make more informed choices in their ODR processes.
Also, optimization techniques, such as genetic algorithms, can be utilized to maximize various criteria. By considering multiple factors such as cost, time, fairness and party preferences, these techniques can suggest the most advantageous ODR approach. Optimization algorithms explore the search space of potential ODR processes and iteratively refine the options to identify the optimal solution.
Recommendation systems are another suitable option in assisting parties with selecting suitable ODR services. By leveraging techniques such as collaborative filtering, content-based filtering and hybrid recommendation systems, parties can receive personalized suggestions based on their preferences, historical data and feedback. These systems analyse the characteristics of previous disputes and the profiles of the parties involved to generate tailored recommendations. Collaborative filtering examines patterns of similarities and preferences among parties to identify relevant ODR services. Content-based filtering focuses on the specific attributes and features of ODR services to match them with parties’ preferences. Hybrid recommendation systems combine both collaborative and content-based approaches to provide comprehensive and accurate suggestions.
Lastly, a field that also gained relevance in the last years is that of Natural Language Processing (NLP). NLP enables the understanding and extraction of pertinent information from textual data, facilitating informed decision-making. Information retrieval techniques in NLP can efficiently search and retrieve relevant ODR resources, legal precedents or scholarly articles to provide parties with comprehensive information, which can in turn support more informed decision-processes. NLP can also enable machine translation of multilingual documents, allowing parties to overcome language barriers and ensure effective communication and access to information. Additionally, AI-powered chatbots equipped with NLP capabilities can offer real-time guidance on ODR options, answering questions and providing support to parties before and throughout the dispute resolution process. By leveraging NLP techniques, parties can benefit from improved information access, communication and guidance, enhancing their ODR experience.
There are, as this section intended to show, a multitude of options through which content can be personalized and tailored to the specific needs and preferences of users. While in this section we focused on the issue of selecting an ODR provider and how such a service could be implemented in a personalized manner, the same applies similarly to other services in the context of ODR. While this concerned the personalization of the content, the next section concerns the personalization of how this content is provided.2.2.2 Personalization of UI/UX
The automatic personalization of UI and/or User Experience (UX) through AI techniques is a challenging goal, requiring the involvement of different fields including AI, User Modelling and Human-Computer Interaction. Two different approaches can generally be followed when personalizing the UI. Either the interface is designed in a modular way so that it can be adapted intelligently and dynamically to the user, or different static interfaces are designed (variants), from which an intelligent process selects the most suited for a specific user/situation. The former would be, in principle, more responsive to the user’s needs but could, in some cases, run ‘out of the control’ of the designer. Moreover, in some cases, the space for adaptation might be reduced by software/device constraints or other requirements (e.g. mandatory fields).
A key concept in realizing this vision is that of plasticity which, in this context, implies that the interface adapts to the needs of a specific user, while showing resilience to the needs of a variety of other users. That is, the interface must perform well for users with different characteristics and, at the end, revert to its initial state, ready to be adapted to the next user. Plasticity, in UI design, thus relates to catering for the specific user’s current physical and mental abilities and state.
Such interfaces can help overcome many different barriers to justice which include physical disabilities, cognitive disabilities and impairments, age-related aspects (including low proficiency with technology) and cultural and knowledge barriers.
Under this view, human abilities are seen as a continuum in a multidimensional space in which the axes represent physical and cognitive characteristics. UIs must thus dynamically adapt to address this continuum. One key challenge in this adaptation is the notion of user awareness or sensitivity, especially since the interface should not burden the user with additional interactions (e.g. questions) to build a representation of the user’s characteristics. This information should instead be acquired in a non-intrusive way. In some cases, a user profile may already exist that may provide relevant information (e.g. age, gender, cultural/geographical background, level of education). Additionally, techniques such as segmentation can be used to find groups of similar or related users and extract their main characteristics. A new user could then be matched to the preferences/needs of similar and already known users. Finally, minimalistic feedback mechanisms can also be incorporated in the interface which allow users to easily report their satisfaction/dissatisfaction towards the interface.
Another source of information may come from the ability of the user herself/himself to adapt the interface. For instance, if the interface has controls that allow the user to select aspects such as language, font type/size and colour schemes, that information can then be stored together with the user’s characteristics, and be used in the future by AI techniques, namely from the field of ML, to automatically define the best UI for other users.
Aside from using ML, other more traditional techniques can also be used. For instance, in the past, the problem of best adapting the UI to a specific user’s characteristics or needs has been dealt with as an optimization problem, in which a user-specific cost function is defined.
In conclusion, there are two key issues in what concerns the adaptation of UI. The first is the modelling of the elements of the UI and their characteristics, as well as the modelling of the user’s characteristics and needs. This can be done using standard notations, such as the previously mentioned XML or JSON, which can then serve as an input for the adaptation phase. The second is, precisely, how to adapt these elements to best meet the user’s requirements. Different techniques can be used for this purpose, with varying degrees of computational complexity and results, including approaches based on Reinforcement Learning, more traditional ML or even optimization.2.2.3 Distributed Training of AI Modules
In recent years, the application of AI has seen a significant development. This has been achieved, thanks to the development of new algorithms by both the research community and the industry, but also at the expense of very large amounts of data. Often, these data were acquired in unethical ways, without explicit consent of the users and with a very low level of transparency. Although these practices allowed for the development of very advanced assets such as generative models or large language models, they are incompatible with current European vision on the collection and use of data, which is designed to protect smaller parties from unfair practices.
We argue that one core aspect is that all the data produced by the actions and/or behaviours of the users remain under the explicit control and ownership of the respective users. That is, the user will not only be explicitly aware of any data that may be collected about them, but also have control over their use, deciding on a case-by-case basis whether to grant access to a certain data asset, given the intended purposes or scope. The sharing of data by one user with a certain service will be seen as an individual contribution towards the development of better services for all.
While this will contribute to decreasing the current power imbalance between people and large private companies in what concerns the use of data, it certainly raises significant technological challenges. One of the most significant concerns is about the training of ML models with distributed, possibly limited and dynamic sources of data.
Below we aim to describe distributed and federated approaches to ML, in which the data is distributed and under the control of their owners, the users.
One of the approaches to consider, already researched in the past by one of the partners, consists in training ML models in the VAP of the users, using the data available locally, and then sharing those individual models with the community. In this way, it is possible to share the trained models, which pose no privacy concerns (or others), without sharing the original data. Then, these models can be combined in the form of Ensembles, through some voting scheme, in which each individual model contributes to the prediction of the Ensemble. This has been shown to work when a certain amount of data is available in each VAP.
In cases in which the amount of data is rather small, alternative methods may be considered such as training a single model by cycling it through the VAPs during the training phase. This is very similar to the concept of batch in a Neural Network, for instance, which is trained in successive iterations of sequential batches of data. The difference, in this case, will be that the batches of data will be distributed across a network of willingly participating VAPs, and the model will cycle through them to increasingly learn.
These two approaches serve merely to show that, albeit challenging, this key vision of the proposal is realistic and technically possible. Other approaches will also be investigated during the project, and the final solution will most likely be a hybrid one, including a combination of several approaches, namely to address well-known issues such as those of the cold start problem or small volumes of available data.
Moreover, a strong focus will be placed on Human-AI collaboration, seen by the team as the only way to develop ethical and responsible AI systems. This includes, among other aspects, adopting approaches such as Active Learning, in which the users may be asked to label certain valuable instances of data for the model to learn from (which minimizes the need for data valuing quality/diversity over quantity), and the inclusion of explainability and transparency by design.
We believe that the users, given control, ownership and responsibility over their data, and with the goals and scope of each AI service being clearly and transparently communicated, will be intrinsically motivated to share their anonymized data, knowing that they will safely contribute to the development of new and empowering services. These services will, in turn, further contribute to decreasing the imbalance of power between large private companies and individual users by fostering competition, and through an open-source approach.2.3 Open Framework for Messaging and Addressing
2.3.1 Introduction and Motivation
Most people in the modern world have uniform access to the Internet, and this access is tractable because the technicalities of this facility are transparent. From a user’s perspective, we interact with a UI (mobile application or a browser window). Behind the scenes, the most widely used UIs rely on HTTP to communicate with one or more backend services. The UI can find such services using URLs,9x The newer term URIs, also denotes the published location of a service, but the owner established an infrastructure that allows the service to be moved internally. Considering the client-server, protocol, such an URI still points to a specific hostname, thus behaving as an URL. which refer to actual locations (the L in Uniform Resource Locator) that serve a particular resource. Typically, a UI is bound to preset HTTP URLs, thus being presented as a system.
We will refer to HTTP further as a familiar starting point to discuss the choice of asynchronous messaging at the core of the ODR architecture.
The HTTP protocol was originally designed to allow a person to present resources to the world by installing a web server.10x As the users and developers innovated, HTTP has been extended for security (HTTPS), sessions, authentication, long-polling for chats, notifications (SSE), streaming (WebRTC), WebSockets etc. This was made possible by the extensibility of HTTP via headers. HTTP is an online, unicast protocol (one-to-one), essentially stateless, with a request-reply exchange pattern (a conversation consists of requesting a resource and the server providing the resource).
However, the HTTP protocol is asymmetric. The owner of the web server provides a service, while many other users consume it. As opposed to its infancy days, where deploying an independent web server was fast and easy, the myriad of fault-tolerance, security and innovations enabled by HTTP made any serious attempt to provide services via HTTP prohibitive outside the realm of professional teams.
On an alternative path, used internally by large technology companies, but not so visible to the end-users, we have asynchronous communication via messages (Message Queueing systems, or MQ). Messaging allows both unicast and multicast communication (one or multiple recipients), and other communication patterns besides request-reply (request-only, notify/reply-only), and, by default, they are symmetric (all parties act both as service providers and service consumers).
In comparison with the HTTP world, where providers deploy web servers, and customers use UI apps to connect to them via TCP/IP, here all users of the system connect their applications through a message broker.11x There is a variety of well-known message brokers available for use (ActiveMQ, Artemis, Kafka, RabbitMQ to name just a few). The broker acts as an intermediary that provides message ordering, and delivery guarantees, adding thus the asynchronous and the possibility of offline communication (queueing messages within the communication platform while a party is unavailable or busy).12x One can think of a HTTP server as a counter, which can only be used when someone is actually serving customers, while an async messaging platform acts like an intermediary that handles communication details – such as a post office or an email system.
At the enterprise level, the applications are implemented in an agreement over a setup of queues and message formats, thus exchanging data in either direction. However, being used mostly internally, message brokers have not been augmented with features that allow global communication. Setting up a few message brokers is quite easy, but it is limited in scale. Tying up together multiple brokers becomes problematic due to addressing conflicts and security (setting up trust relations between brokers does not imply trust between the applications using the broker). This is also true for cloud messaging services.
In our view, ODR processes require a symmetric relation between the parties, where each party can fully represent itself in the online world (by holding copies of proofs, and the history of the resolution process). The parties need to have cheap, open access to the system. Also, the requirements of ODR involve safe, distributed data storage, multicast communication and notifications of events.
Async communication via message brokers fulfils all the requirements for ODR. We will examine the opportunity of relying on a messaging infrastructure, with the target of providing symmetric, secure and scalable ODR processes. We believe such a messaging platform is technically feasible, by leveraging advances in HTTP that lead to its global use. At the same time, we examine how a messaging platform can be set up to provide easy access for users, eliminating the large cost of complex infrastructure.2.3.2 Advantages of Async Messaging
One aspect under consideration is that messaging platforms allow for several types of exchange patterns, including the above-mentioned request-reply pattern from HTTP, but they also provide request-only and notify (response-only). Each message can be cheaply broadcast to multiple parties (multicast) since the mechanism is implemented by the messaging platform instead of the application code and infrastructure.
The current client-server applications are quite proficient at implementing unicast request-reply interactions. However, the need for multicast and using the notify pattern has arisen recently, as the systems became more complex and integrated. Attempts to solve it in the traditional HTTP way have encountered the barrier of the high cost of client-side setup. Current solutions require polling or maintaining a constant client-to-server connection which is, again, expensive on the HTTP server and the TCP infrastructure. As such, most implementations have turned to out-of-band interaction via SMS, email or similar methods, while investing massive resources to support scalable short-term communication for small-sized online notifications (such as for chat applications or page updates).
In a messaging system, all parties involved have a dual role of both client and server. Each application connected to the system will have some queues where it awaits requests, and connects to other parties’ queues to send requests. This makes the system symmetric, as opposed to the pervasively used HTTP system (where the intent is to ease client setup for many clients, while servers require expensive setup and maintenance for 100% availability).
Moreover, the messaging system stores sent messages while the destination is offline, similar to SMS and emails, mentioned above. This allows the automation of lengthy, sparse processes since events in an ODR case occur at a slower pace than current online applications can handle.13x Current applications notify users by email or other means when offline events occur. This paradigm became ubiquitous due to technical limitations, and has created a culture where the email address has become a central point of one’s digital identity.
There is also the side-effect that async communication mediated by message brokers would allow ODR VAPs to be intermittently online, which will lower the cost and energy requirements for each participant, and, as a result, for the entire system.2.3.3 Async Messaging Platform
The ODR messaging platform integrates available open-source brokers, leveraging existing protocols and technology. It is open to extension by interested organizations or individuals, which can make use of ODR by connecting their privately owned message brokers to the ODR messaging platform.
The fundamental metaphor for understanding the async messaging platform is a store-and-forward network of brokers, which provides specific messaging features that will be essential for ODR:Message delivery guarantees: messages should not be lost along the way. This alleviates the need for applications to contact the target server directly, in order to confirm delivery of data because they can rely on the messaging platform to achieve the task. Applications can confirm the successful processing of their event via process-related events, unrelated to the communication protocol. One can specify requirements for delivery by using message meta-headers that are interpreted by the platform.
Message ordering: messages should be received in the order they are sent by the application. Applications can request in-order delivery using message meta-headers for a certain endpoint. However, this will lessen the performance and scalability of these particular features.
Service availability: the availability requirement that usually sits on the shoulder of each application implementer is now delegated to the messaging platform. However, if using a local broker, even the platform requirements for 100% availability can be lowered, while still achieving message ordering and delivery guarantees.
ODR users and organizations have various options for connecting to the global messaging platform, depending on their preferences. The options range from:
deploying the publicly available open-source brokers on their own private infrastructure, and connecting it to the global messaging platform to
connecting directly to a public cloud message broker belonging to our organization to
deploying a private cloud message broker from our offer, which can be used for ODR, as well as other integrations.
This variety of options allows free, open access to the messaging platform, which is an essential part of providing justice via ODR. One should avoid creating an ODR system that is dependent on a specific platform provider: any user can deploy a broker at home and connect it to the global platform.
Reliance on existing standards and protocols promotes adoption, longevity and low-cost interoperability with new and existing solutions. A good starting point is the Java Messaging Standard (JMS), which is built to realize the above-mentioned features: delivery guarantees, message ordering, etc. The JMS standard is used in critical systems, and the open-source brokers that implement it are well-established, solid choices. The JMS platform core can be interfaced with other non-JMS brokers via transformation layers, including HTTP services.2.3.4 Global Application Addresses
Traditional message queues are restricted to a local broker or cluster of brokers that support an application, or a small number of applications at an organizational scope. The ODR system requires a global addressing system, where users are able to address the endpoints of any application attached to the messaging platform. Existing brokers can be customized either using plug-ins, or their code can be adapted progressively. As a plus, this can be done in a way that also enables pre-existing applications to transition to the new addressing system.
Within enterprise-level use (initially called ESB – Enterprise Service Bus), the administrators need to ensure there are no conflicts within the endpoint names used by each async application attached to the brokers. A well-established solution is for each application to use a prefix for all its endpoints, possibly configurable, to ensure no conflicts. These endpoints need to be wired together by the administrator, depending on the characteristics of deployment. In effect, the same process is performed by all operators of HTTP-based services, including micro-services, where each application needs to be configured with all base URLs of adjacent services.
Addressing the idea of a global async network, the messaging platform requires a different paradigm: separating the location of the application (e.g. the URLs – Uniform Resource Locators) from the actual identity of the application (the URIs – Uniform Resource Identifiers, or better yet, URNs – Uniform Resource Names).
Each deployment of a particular application has a specific identity, which can be seen as logically compounded by the (a) deployment identity and (b) the application identity. This becomes the globally unique base of the resources and services provided by the deployment, i.e. the application address. As one can see, this creates a symmetric relation between deployments, as opposed to the client-server model, where the clients need to be configured with the location14x The location-identity duality transpired into equivalent use of the terms URL (location) and URI (identifier). However, one must note that an URL implies server identity, while an identity does not imply a location. of the server.
Global addressing can be supported for brokers deployed on-premise, either within the broker code, where possible or via a mapping in the connectivity to the rest of the broker network.2.3.5 Identities
Current online applications manage client identities and credentials server-side, and require users to authenticate to the server in order to validate their identity. The authentication mechanisms in use are mostly a pair of username (or email) and password, combined with one-time passwords, SMS authentication codes and authenticator apps. Users can also choose OAuth, or similar mechanisms, which enable servers to use a third-party service for authentication.
In essence, the above establishes a relation of trust between the browser session and the server, where the server trusts incoming requests as being authored by the authenticated person. The client’s trust in the server usually relies on TLS certification authority certificates, usually pre-installed in browsers and operating systems. In theory, clients can also request personal certificates, but this mechanism is rarely used due to the associated cost on the client side.15x Service providers have to support the costs server-side, but the economical interest in enlarging the user base pushed the technology away from using TLS client authentication, i.e. from using paid personal certificates.
We propose using similar mechanisms to authenticate users when managing their accounts. The other methods presented below are better suitable for use within messaging. However, when using a browser, it is preferable to use suitable, well-established mechanisms.
MQ applications present a set of credentials when connecting to a broker within enterprise use. In our terminology, these connection credentials are simply protocol details, and they are not the target of this section. In an enterprise setup, the connection credentials validate both the client code and the messages sent by that application, since both are under the broker’s administrator’s control. Such trust is not present in a global messaging network, where any address can be used by malicious actors.
Within the global messaging platform, the applications create identities and use them for various roles. Async applications act both as clients and servers, which means the trust relations need to be bidirectional: application A needs to trust incoming messages are indeed created by application B, and, conversely, messages sent back from B to A need to be trusted by A. There are mechanisms that create sessions in request-reply exchanges, but, essentially, a third party can also intersperse messages into the same queue within the dialogue. This raises the need for applications to check the origin of each message, i.e. to authenticate the identity of the sender.
Applications define security domains for their endpoints, validating messages against their trust database. Some of their queues may need to accept untrusted messages, in order to bootstrap the trust process (unless there is a separate method for communicating the credentials). Secure queues should require incoming messages to be signed, encrypted or both.
The support for establishing deployment identities will assist clients and developers in creating and deploying applications. Based on user identities, deployment identities and application identities, developers can provide the necessary signing and encryption libraries for secure communication between applications. However, implementers can choose their own authentication and trust mechanisms and rely solely on the application address.2.3.6 Async Messaging within VAPs
Each VAP will be owned by an individual, or shared by a group of people with shared interests, such as a family or an institution. For brevity, we will refer to either of these as “a user”.16x Organizations can register user accounts on the VAPs, assigning each account various roles.
Besides management services, VAPs offer services related to ODR processes, data storage services and automated agents. Each of these services has well-defined endpoints where commands can be issued, or notifications are processed.
The final communication architecture would be: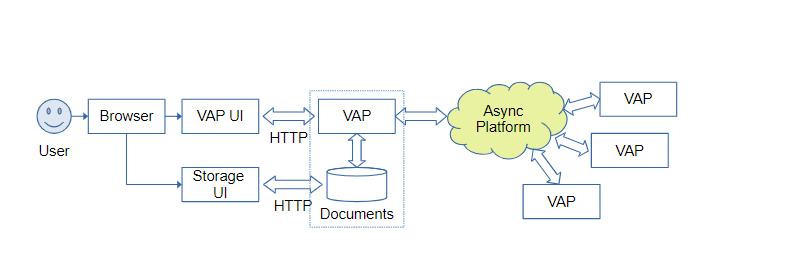
Once a VAP is initialized by the VAP machine, the user will have to assign an identity to the VAP. Alternatively, the VAP identity can be mapped onto the user’s identity, and serve as the deployment identity component of the VAP’s async global addresses. Each application running on the VAP machine will, in accordance with the above, receive a specific global address. The developers of the application define a set of inbound endpoints relative to the application’s global address and use these within ODR BPMN processes. Each message send operation refers to a destination endpoint that incorporates the target VAP global address, so the message is sent to the appropriate entity within the process.
It is the responsibility of the messaging platform to ensure the delivery of these messages to the VAP machines. Note that, in opposition to currently used technologies, VAPs can be run intermittently, since the messages will be temporarily queued on the platform until the VAP becomes reachable again. This allows long-running, sparse ODR processes to be resilient and efficiently implemented.2.3.7 Distributed ODR Processes
In a concrete example, let us consider the VAP for a fictional ACME corporation. To bootstrap the VAP, the administrators will create a company identity for the VAP. The ODR applications on the VAP will have global addresses compound of the company identity and the application identity (ODR UI, Complaint manager, document storage etc.). As a result, the queues provided by the ODR BPMNs will be prefixed by this address. Another user can file a complaint directly at ACME by selecting ACME’s VAP address in his own VAP’s UI. This is similar to typing a website address in a browser.17x The AI-assisted user interface can help locate the appropriate ODR provider VAP, depending on the user complaint. To file the complaint, the user’s VAP will send messages, via the messaging platform, to ACME’s VAP, according to the appropriate BPMN process. The complaint inbox queue should accept untrusted identities and register the requester’s identity within the newly started ODR case.
In concrete terms, the ACME Corp. might register a VAP similar to urn:identity:ACME-ODR,18x The URNs here are logical endpoint addresses. The actual representation might differ. thus the VAP will present a set of global address prefixes similar to urn:async-app:ACME-ODR/VAP-UI, urn:async-app:ACME-ODR/ComplaintManager, urn:async-app:ACME-ODR/DocumentStorage. Finally, we can envision endpoints such as urn:async-endpoint:ACME-ODR/ComplaintManager:Inbox.NewComplaints and urn:async-endpoint:ACME-ODR/DocumentStorage:Document.Updated.
In the example above, the application addresses ACME-ODR/ComplaintManager are suffixed by the complaint-manager application’s queues, such as Inbox.NewComplaints. The user applications import the ACME-ODR identity, and relay their own identity, as plaintiffs, alongside the initial complaint form. The ODR process on ACME-ODR will further refer to the digital identity of the plaintiff based on this identity (let us call her Alice),19x Alice and Bob are names usually used in illustrating computer communication protocols. See https://en.wikipedia.org/wiki/Alice_and_Bob. such as urn:async-app:Alice/BPMN-Case:Case123.Document.Request. The actual endpoint names, process/case numbering are defined by the BPMN process in question.
In line with the symmetry principle mentioned above, Alice’s VAP also processes requests addressed to her. Another person, like Bob, or even the ACME institution, can use their VAPs to fire a complaint at urn:async-endpoint:Alice/ComplaintManager:Inbox.NewComplaints, and start a new ODR case, where Bob or ACME is the plaintiff. As the ODR processes continues, the two VAPs will enrol other VAPs as well, perhaps belonging to courts, judges or arbitration institutions.2.3.8 Data Spaces
Each VAP runs services related to data storage. Users enter data in forms, or they upload documents, as required by the dispute resolution processes. This data is managed by the VAP, under the user’s governance.
As part of ODR processes, other parties will need access to some of the user’s data. The user will have to allow these parties to copy these documents onto their own VAPs. The integrity of the data can be guaranteed by cryptographic digital signatures, and privacy via encryption. Where required, the digital identity of the owner can be verified by inspecting the digital signature of the document.
Other ODR processes can be authored so that they only view the user’s data temporarily, without requesting a copy. The VAP can provide a link to the document, or, by making use of the VAP’s internal AI services, extract the needed information, without providing access to the full document. Further tampering can be prevented by the VAP providing the document’s digital signature, ensuring the document contents were not changed since the time of the request.
VAP users can access personal benefits from the data gathered on the VAP. Local AI services can be trained on the user’s data, in order to enhance the experience, personalize forms and find meaningful ODR providers. The training can take place locally, on the VAP, without any data leaks, and the enhanced models remain on the user’s VAP.
Users can also choose to use public AI services, and also participate in the training of third-party AI models. The data access mechanism can be implemented in a similar fashion to that in the ODR process, by making copies of the data (possibly anonymized) or training the remote model without making a foreign copy of the data.
The proposed data space is thus governed by the ODR users, enhancing privacy and control for all parties.
The above features are derived from the necessities imposed by ODR onto personal data storage. The result is aligned with other initiatives regarding data spaces, such as the Solid server from Inrupt20x https://www.inrupt.com. and Common European Data Spaces,21x https://dataspaces.info/common-european-data-spaces/; https://dssc.eu. suggesting there is an opportunity for investigating and, maybe, integrating VAPs with such data spaces. -
3 Final Remarks
Our new concept described in this article will hopefully lead to one or more proofs of concept and proofs of technology. During these projects, critical issues will be what should be the new self-governance of the alternative open ODR environment we described in this article, alongside valid legal regulations. Key for the self-governance might be service providers.
Service providers will be entities/persons who will provide services to the VAPs and publicly available AI services provided to VAP users. The services might include maintenance, development and quality monitoring. Service providers might be authenticated through a DNS record and the web of trust. Service providers may also be self-provided, which means that they will provide the services to themselves. For example, also ODR institutions can be service providers – to themselves or to other ODR providers interested in their services.
In addition, there will probably need to be rules governing the provision of public AI services as services which are available to everybody under open specification publicly available for free. Public AI services will apply open data standards, including for messaging and addressing. The digital space in which the open AI services will be provided might be called Common Online Space. Common Online Space is formed by anonymized data, messaging and addressing infrastructure, open specifications, governance rules (if any) and (accredited or self-accredited) service providers. Or should we understand the Common Online Space only as a set of rules and open specifications, i.e. without any data or concrete service providers?
It will be interesting to discuss what such self-governing rules should be: (i) ethical charter? (ii) limitation of maximum amount of shared anonymized data to which a user has access? (iii) what benefits will apply to users who voluntarily share their anonymized data (e.g. lower subscription)? And another question: should there be an efficient ODR mechanism available for all users to resolve their issues related to the operation of the open ODR environment and the service providers? There are many questions which need to be clarified during the first project. - * This contribution is based on research carried out in the framework of the DG Justice-supported project or the e-Justice ODR scheme (GA n. 101046468).
-
1 Top authorities on this topic are Ayelet Sela and David Larson.
-
2 Based on discussions with ODR experts, including Ayelet Sela and David Larson.
-
3 This is very well demonstrated by Paula Hannaford-Agor in her article, Director, Center for Jury Studies, NCSC, “How exactly does it get done here?” Conducting cross-jurisdictional research with judges and court staff.
-
4 E-Justice ODR Scheme, DG JUST 101046468.
-
5 Paula Hannaford-Agor, Director, Center for Jury Studies, NCSC, “How exactly does it get done here?” Conducting cross-jurisdictional research with judges and court staff.
-
6 Ibid.
-
7 Research sub-project under the E-Justice ODR Scheme.
-
8 See above note 9.
-
9 The newer term URIs, also denotes the published location of a service, but the owner established an infrastructure that allows the service to be moved internally. Considering the client-server, protocol, such an URI still points to a specific hostname, thus behaving as an URL.
-
10 As the users and developers innovated, HTTP has been extended for security (HTTPS), sessions, authentication, long-polling for chats, notifications (SSE), streaming (WebRTC), WebSockets etc. This was made possible by the extensibility of HTTP via headers.
-
11 There is a variety of well-known message brokers available for use (ActiveMQ, Artemis, Kafka, RabbitMQ to name just a few).
-
12 One can think of a HTTP server as a counter, which can only be used when someone is actually serving customers, while an async messaging platform acts like an intermediary that handles communication details – such as a post office or an email system.
-
13 Current applications notify users by email or other means when offline events occur. This paradigm became ubiquitous due to technical limitations, and has created a culture where the email address has become a central point of one’s digital identity.
-
14 The location-identity duality transpired into equivalent use of the terms URL (location) and URI (identifier). However, one must note that an URL implies server identity, while an identity does not imply a location.
-
15 Service providers have to support the costs server-side, but the economical interest in enlarging the user base pushed the technology away from using TLS client authentication, i.e. from using paid personal certificates.
-
16 Organizations can register user accounts on the VAPs, assigning each account various roles.
-
17 The AI-assisted user interface can help locate the appropriate ODR provider VAP, depending on the user complaint.
-
18 The URNs here are logical endpoint addresses. The actual representation might differ.
-
19 Alice and Bob are names usually used in illustrating computer communication protocols. See https://en.wikipedia.org/wiki/Alice_and_Bob.
-
21 https://dataspaces.info/common-european-data-spaces/; https://dssc.eu.
International Journal of Online Dispute Resolution |
|
| Article | Personalized e-Justice ODR Forms |
| Keywords | ODR, e-justice, access to justice, digitally disadvantaged persons, vulnerable persons, personalized ODR forms, diversity by design, AI, distributed training of AI models, digital mapping, BPMN, Json, cybersecurity, protection of privacy, anonymized shari |
| Authors | Zbynek Loebl, Davide Carneiro, Ciprian Ciubotariu en Tereza Rezabkova * xThis contribution is based on research carried out in the framework of the DG Justice-supported project or the e-Justice ODR scheme (GA n. 101046468). |
| DOI | 10.5553/IJODR/235250022023010001009 |
|
Show fullscreen Abstract Author's information Statistics Citation |
| This article has been viewed times. |
| This article been downloaded 0 times. |
Zbynek Loebl, Davide Carneiro, Ciprian Ciubotariu e.a. , "Personalized e-Justice ODR Forms", International Journal of Online Dispute Resolution, 1, (2023):97-122
|
There are two critical assumptions for improving access to online justice: (i) effective control of data by those who generate the data; and (ii) symetric relation between the parties. Based on these critical assumptions, new approaches to e-justice ODR procedures and new AI based publicly available services should be adopted as well as new online technology. Not only the ODR institutions but even the parties, including people and importantly also persons with digital disadvantages, will have their own independent online platforms with their data storages, personalized ODR forms continuously improved by new AI-based services and asynchronous digital communication among platforms at a mass scale. Such platforms will be defined as VAPs (Virtual Agent Platforms). Thanks to the possibility for the parties to personalize their VAPs, it will be easier and more efficient to achieve diversity by design in access to online justice as the collaboration among users-data generators will provide a crucial asset. |